





关于Java中的String(二)
Java8中的StringJoiner
StringJoiner是java.util包中的一个类,用于构造一个由分隔符分隔的字符序列(可选),并且可以从提供的前缀开始并以提供的后缀结尾。虽然这也可以在StringBuilder类的帮助下在每个字符串之后附加分隔符,但StringJoiner提供了简单的方法来实现,而无需编写大量代码。
如何使用
1 | public class StringJoinerTest { |
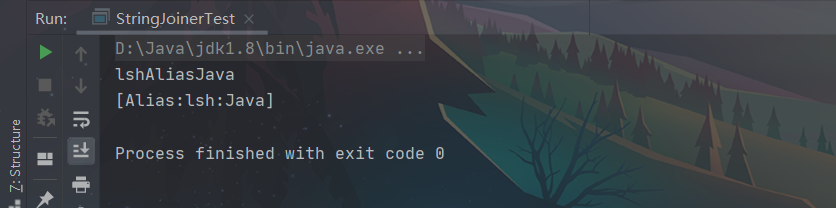
值得注意的是,当我们StringJoiner(CharSequence delimiter)初始化一个StringJoiner的时候,这个delimiter其实是分隔符,并不是可变字符串的初始值。
StringJoiner(CharSequence delimiter,CharSequence prefix,CharSequence suffix)的第二个和第三个参数分别是拼接后的字符串的前缀和后缀。
原理
1 | public StringJoiner add(CharSequence newElement) { |
可以看出,StringJoiner其实就是依赖StringBuilder实现的,因此,我们可以猜到他的性能损耗应该和直接使用StringBuilder差不多
用StringJoiner的原因
Java8中提供了StringJoiner在丰富了Steam的用法,而且StringJoiner也可以方便增加前缀和后缀。
最后,StringJoiner其实是通过StringBuilder实现的,所以他的性能和StringBuilder差不多,他也是非线程安全的。
在日常开发中,要进行字符串拼接:
1、如果只是简单的字符串拼接,考虑直接使用”+”即可。
2、如果是在for循环中进行字符串拼接,考虑使用StringBuilder和StringBuffer。
3、如果是通过一个List进行字符串拼接,则考虑使用StringJoiner。
String.valueOf和Integer.toString区别
1 | int i = 3; |
我们有以上三种方法将一个int类型转成String类型
第三行和第四行没有区别,因为String.valueOf(i);也是调用Integer.toString(i);来实现
第二行其实是String i1 = (new StringBuilder()).append(i).toString();
switch对整型、字符型和字符串支持的实现
整型
1 | public class switchDemo { |
反编译后
1 | public class switchDemo |
我们可以看出其对int的判断就是直接比较整数的值
字符型
1 | public class switchDemoChar { |
反编译后
1 | public class switchDemoChar |
可以看出对字符型比较的时候实际上是比较的ascii码
字符串
1 | public class switchDemoString { |
反编译后
1 | public class switchDemoString |
我们可以看出其是通过equals()和hashCode()方法来实现的。
所以,其实switch只支持一种数据类型,那就是整型,其他数据类型都是转换成整型之后再使用switch的
重写 equals 时为什么一定要重写 hashCode?
上文中我们看到了equals和hashCode方法,那么这时我们就想起了一个经典问题:重写 equals 时为什么一定要重写 hashCode?equals 方法和 hashCode 方法是 Object 类中的两个基础方法,它们共同协作来判断两个对象是否相等。为什么要这样设计嘞?原因就出在“性能” 2 字上。使用过 HashMap 我们就知道,通过 hash 计算之后,我们就可以直接定位出某个值存储的位置了,那么试想一下,如果你现在要查询某个值是否在集合中?如果不通过 hash 方式直接定位元素(的存储位置),那么就只能按照集合的前后顺序,一个一个的询问比对了,而这种依次比对的效率明显低于 hash 定位的方式。这就是 hash 以及 hashCode 存在的价值。
当我们对比两个对象是否相等时,我们就可以先使用 hashCode 进行比较,如果比较的结果是 true,那么就可以使用 equals 再次确认两个对象是否相等,如果比较的结果是 true,那么这两个对象就是相等的,否则其他情况就认为两个对象不相等。这样就大大的提升了对象比较的效率,这也是为什么 Java 设计使用 hashCode 和 equals 协同的方式,来确认两个对象是否相等的原因。
那为什么不直接使用hashCode就确定两个对象是否相等呢?因为不同对象的hashCode可能相同,但hashCode不同的对象一定不相等。
但即使知道了以上基础知识,依然解决不了本篇的问题,也就是:重写 equals 时为什么一定要重写 hashCode?要想了解这个问题的根本原因,我们还得先从这两个方法开始说起。
1、equals
Object 类中的 equals 方法用于检测一个对象是否等于另外一个对象。在 Object 类中,这个方法将判断两个对象是否具有相同的引用。如果两个对象具有相同的引用,它们一定是相等的。
因此在大多数情况来说,equals 的判断是没有什么意义的,例如,使用 Object 中的 equals 比较两个自定义的对象是否相等,这就完全没有意义(因为无论对象是否相等,结果都是 false)。
1 | public class EqualsMyClassExample { |
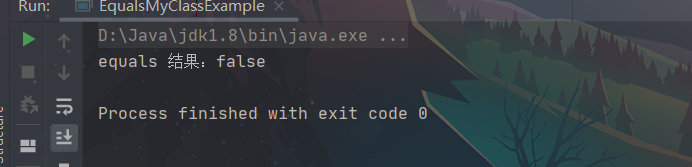
因此通常情况下,我们要判断两个对象是否相等,一定要重写 equals 方法,这就是为什么要重写 equals 方法的原因。
2、hashCode方法
需要注意的是:散列码是没有规律的。如果 x 和 y 是两个不同的对象,x.hashCode() 与 y.hashCode() 基本上不会相同;但如果 a 和 b 相等,则 a.hashCode() 一定等于 b.hashCode()。
3、为什么要一起重写?
我们来看一下示例
1 | import java.util.HashSet; |
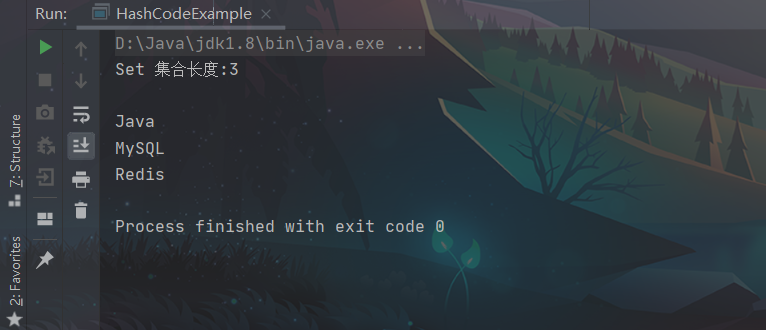
我们知道,Set集合最大的特点就是去重
然后,当我们在set中存储的是只重写了equals方法的自定义对象时,有趣的现象发生了:
1 | package com.test; |
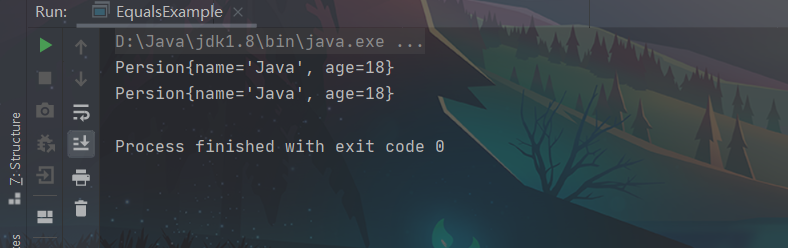
从上述代码和上述图片可以看出,即使两个对象是相等的,Set 集合竟然没有将二者进行去重与合并。这就是重写了 equals 方法,但没有重写 hashCode 方法的问题所在。
4、原因
如果只重写了 equals 方法,那么默认情况下,Set 进行去重操作时,会先判断两个对象的 hashCode 是否相同,此时因为没有重写 hashCode 方法,所以会直接执行 Object 中的 hashCode 方法,而 Object 中的 hashCode 方法对比的是两个不同引用地址的对象,所以结果是 false,那么 equals 方法就不用执行了,直接返回的结果就是 false:两个对象不是相等的,于是就在 Set 集合中插入了两个相同的对象。
字符串池
我们可以用以下两种方式创建字符串
1 | String str = "Alias"; |
而第一种是我们比较常用的做法,这种形式叫做”字面量”。
在JVM中,为了减少相同的字符串的重复创建,为了达到节省内存的目的。会单独开辟一块内存,用于保存字符串常量,这个内存区域被叫做字符串常量池。
当代码中出现双引号形式(字面量)创建字符串对象时,JVM 会先对这个字符串进行检查,如果字符串常量池中存在相同内容的字符串对象的引用,则将这个引用返回;否则,创建新的字符串对象,然后将这个引用放入字符串常量池,并返回该引用。
这种机制,就是字符串驻留或池化。
Class常量池
Class常量池可以理解为是Class文件中的资源仓库。 Class文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池(constant pool table),用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References)。
Class文件中的前八个字母是cafe babe,这就是Class文件的魔数
字面量
说简单点,字面量就是指由字母、数字等构成的字符串或者数值。
字面量只可以右值出现
符号引用
符号引用是编译原理中的概念,是相对于直接引用来说的。主要包括了以下三类常量: * 类和接口的全限定名 * 字段的名称和描述符 * 方法的名称和描述符
Class常量池有什么用
首先,可以明确的是,Class常量池是Class文件中的资源仓库,其中保存了各种常量。而这些常量都是开发者定义出来,需要在程序的运行期使用的。
Class是用来保存常量的一个媒介场所,并且是一个中间场所。在JVM真的运行时,需要把常量池中的常量加载到内存中。
运行时常量池
运行时常量池( Runtime Constant Pool)是每一个类或接口的常量池( Constant_Pool)的运行时表示形式。
它包括了若干种不同的常量:从编译期可知的数值字面量到必须运行期解析后才能获得的方法或字段引用。运行时常量池扮演了类似传统语言中符号表( SymbolTable)的角色,不过它存储数据范围比通常意义上的符号表要更为广泛。
每一个运行时常量池都分配在 Java 虚拟机的方法区之中,在类和接口被加载到虚拟机后,对应的运行时常量池就被创建出来。
intern
在JVM中,为了减少相同的字符串的重复创建,为了达到节省内存的目的。会单独开辟一块内存,用于保存字符串常量,这个内存区域被叫做字符串常量池。
当代码中出现双引号形式(字面量)创建字符串对象时,JVM 会先对这个字符串进行检查,如果字符串常量池中存在相同内容的字符串对象的引用,则将这个引用返回;否则,创建新的字符串对象,然后将这个引用放入字符串常量池,并返回该引用。
除了以上方式之外,还有一种可以在运行期将字符串内容放置到字符串常量池的办法,那就是使用intern
intern的功能很简单:
在每次赋值的时候使用 String 的 intern 方法,如果常量池中有相同值,就会重复使用该对象,返回对象引用。
String有没有长度限制
我们可以从String类中很多重载的构造函数中看到
1 | public String(byte bytes[], int offset, int length) |
这里面的length使用int类型定义的,所以可以说String定义的时候最大的支持长度就是int的最大范围,为2^31-1;
那么是否这个就是String支持的最大长度了呢?
其实不然,这个值只是在运行期,而实际上,在编译期,定义字符串的时候也是有长度限制的。
1 | String s = "11111...1111";//其中有10万个字符"1" |
当我们执行javac编译时,会抛出异常说常量字符串过长,这是为什么呢?
因为定义String的时候,”xxx”类似这样为字面量,字面量在编译之后会以常量的形式进入Class常量池
关于常量池的限制
CONSTANT_Utf8_info 结构用于表示字符串常量的值:
1 | CONSTANT_Utf8_info { |
u2表示两个字节的无符号数,为16位,最大值为2^16-1=65535
也就是说Class文件中常量池规定了字符串常量长度不能超过65535
但是在javac中代码显示,当参数类型为String,并且长度大于等于65535的时候,就会导致编译失败。
1 | private void checkStringConstant(DiagnosticPosition var1, Object var2) { |
当我们尝试65534个字符时,则会发现可以正常编译